39 KiB
- Programming
- Announcements
- COMMENT Local Variables
Programming programming
All posts in here will have the category set to programming.
Using MinIO to upload to a local S3 bucket in Django python django minio docker dockercompose
So MinIO its an object storage that uses the same API as S3, which means that we can use the same S3 compatible libraries in Python, like Boto3 and django-storages.
The setup
Here's the docker-compose configuration for my django app:
version: "3"
services:
app:
build:
context: .
volumes:
- ./app:/app
ports:
- 8000:8000
depends_on:
- minio
command: >
sh -c "python manage.py migrate &&
python manage.py runserver 0.0.0.0:8000"
minio:
image: minio/minio
ports:
- 9000:9000
environment:
- MINIO_ACCESS_KEY=access-key
- MINIO_SECRET_KEY=secret-key
command: server /export
createbuckets:
image: minio/mc
depends_on:
- minio
entrypoint: >
/bin/sh -c "
apk add nc &&
while ! nc -z minio 9000; do echo 'Wait minio to startup...' && sleep 0.1; done; sleep 5 &&
/usr/bin/mc config host add myminio http://minio:9000 access-key secret-key;
/usr/bin/mc mb myminio/my-local-bucket;
/usr/bin/mc policy download myminio/my-local-bucket;
exit 0;
"appis my Django app. Nothing new here.miniois the MinIO instance.createbucketsis a quick instance that creates a new bucket on startup, that way we don't need to create the bucket manually.
On my app, in settings.py:
# S3 configuration
DEFAULT_FILE_STORAGE = "storages.backends.s3boto3.S3Boto3Storage"
AWS_ACCESS_KEY_ID = os.environ.get("AWS_ACCESS_KEY_ID", "access-key")
AWS_SECRET_ACCESS_KEY = os.environ.get("AWS_SECRET_ACCESS_KEY", "secret-key")
AWS_STORAGE_BUCKET_NAME = os.environ.get("AWS_STORAGE_BUCKET_NAME", "my-local-bucket")
if DEBUG:
AWS_S3_ENDPOINT_URL = "http://minio:9000"
If we were in a production environment, the AWS_ACCESS_KEY_ID,
AWS_SECRET_ACCESS_KEY and AWS_STORAGE_BUCKET_NAME would be read from the
environmental variables, but since we haven't set those up and we have
DEBUG=True, we are going to use the default ones, which point directly to
MinIO.
And that's it! That's everything you need to have your local S3 development environment.
Testing
First, let's create our model. This is a simple mock model for testing purposes:
from django.db import models
class Person(models.Model):
"""This is a demo person model"""
first_name = models.CharField(max_length=50)
last_name = models.CharField(max_length=50)
date_of_birth = models.DateField()
picture = models.ImageField()
def __str__(self):
return f"{self.first_name} {self.last_name} {str(self.date_of_birth)}"Then, in the Django admin we can interact with our new model:


If we go to the URL and change the domain to localhost, we should be able to
see the picture we uploaded.

Bonus: The MinIO browser
MinIO has a local objects browser. If you want to check it out you just need to go to http://localhost:9000. With my docker-compose configuration, the credentials are:
username: access-key
password: secret-key

On the browser, you can see your uploads, delete them, add new ones, etc.

Conclusion
Now you can have a simple configuration for your local and production environments to work seamlessly, using local resources instead of remote resources that might generate costs for the development.
If you want to check out the project code, you can check in my Gitlab here: https://gitlab.com/rogs/minio-example
See you in the next one!
How to create a celery task that fills out fields using Django python celery django docker dockercompose
Hi everyone!
It's been way too long, I know. In this oportunity, I wanted to talk about asynchronicity in Django, but first, lets set up the stage:
Imagine you are working in a library and you have to develop an app that allows users to register new books using a barcode scanner. The system has to read the ISBN code and use an external resource to fill in the information (title, pages, authors, etc.). You don't need the complete book information to continue, so the external resource can't hold the request.
How can you process the external request asynchronously? 🤔
For that, we need Celery.
What is Celery?
Celery is a "distributed task queue". Fron their website:
> Celery is a simple, flexible, and reliable distributed system to process vast amounts of messages, while providing operations with the tools required to maintain such a system.
So Celery can get messages from external processes via a broker (like Redis), and process them.
The best thing is: Django can connect to Celery very easily, and Celery can access Django models without any problem. Sweet!
Lets code!
Let's assume our project structure is the following:
- app/
- manage.py
- app/
- __init__.py
- settings.py
- urls.pyCelery
First, we need to set up Celery in Django. Thankfully, Celery has an excellent documentation, but the entire process can be summarized to this:
In app/app/celery.py:
import os
from celery import Celery
# set the default Django settings module for the 'celery' program.
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "app.settings")
app = Celery("app")
# Using a string here means the worker doesn't have to serialize
# the configuration object to child processes.
# - namespace='CELERY' means all celery-related configuration keys
# should have a `CELERY_` prefix.
app.config_from_object("django.conf:settings", namespace="CELERY")
# Load task modules from all registered Django app configs.
app.autodiscover_tasks()
@app.task(bind=True)
def debug_task(self):
"""A debug celery task"""
print(f"Request: {self.request!r}")What's going on here?
- First, we set the
DJANGO_SETTINGS_MODULEenvironment variable - Then, we instantiate our Celery app using the
appvariable. - Then, we tell Celery to look for celery configurations in the Django settings
with the
CELERYprefix. We will see this later in the post. - Finally, we start Celery's
autodiscover_tasks. Celery is now going to look fortasks.pyfiles in the Django apps.
In /app/app/__init__.py:
# This will make sure the app is always imported when
# Django starts so that shared_task will use this app.
from .celery import app as celery_app
__all__ = ("celery_app",)
Finally in /app/app/settings.py:
...
# Celery
CELERY_BROKER_URL = env.str("CELERY_BROKER_URL")
CELERY_TIMEZONE = env.str("CELERY_TIMEZONE", "America/Montevideo")
CELERY_RESULT_BACKEND = "django-db"
CELERY_CACHE_BACKEND = "django-cache"
...
Here, we can see that the CELERY prefix is used for all Celery configurations,
because on celery.py we told Celery the prefix was CELERY
With this, Celery is fully configured. 🎉
Django
First, let's create a core app. This is going to be used for everything common
in the app
$ python manage.py startapp core
On core/models.py, lets set the following models:
"""
Models
"""
import uuid
from django.db import models
class TimeStampMixin(models.Model):
"""
A base model that all the other models inherit from.
This is to add created_at and updated_at to every model.
"""
id = models.UUIDField(primary_key=True, default=uuid.uuid4)
created_at = models.DateTimeField(auto_now_add=True)
updated_at = models.DateTimeField(auto_now=True)
class Meta:
"""Setting up the abstract model class"""
abstract = True
class BaseAttributesModel(TimeStampMixin):
"""
A base model that sets up all the attibutes models
"""
name = models.CharField(max_length=255)
outside_url = models.URLField()
def __str__(self):
return self.name
class Meta:
abstract = TrueThen, let's create a new app for our books:
python manage.py startapp books
And on books/models.py, let's create the following models:
"""
Books models
"""
from django.db import models
from core.models import TimeStampMixin, BaseAttributesModel
class Author(BaseAttributesModel):
"""Defines the Author model"""
class People(BaseAttributesModel):
"""Defines the People model"""
class Subject(BaseAttributesModel):
"""Defines the Subject model"""
class Book(TimeStampMixin):
"""Defines the Book model"""
isbn = models.CharField(max_length=13, unique=True)
title = models.CharField(max_length=255, blank=True, null=True)
pages = models.IntegerField(default=0)
publish_date = models.CharField(max_length=255, blank=True, null=True)
outside_id = models.CharField(max_length=255, blank=True, null=True)
outside_url = models.URLField(blank=True, null=True)
author = models.ManyToManyField(Author, related_name="books")
person = models.ManyToManyField(People, related_name="books")
subject = models.ManyToManyField(Subject, related_name="books")
def __str__(self):
return f"{self.title} - {self.isbn}"
Author, People, and Subject are all BaseAttributesModel, so their fields
come from the class we defined on core/models.py.
For Book we add all the fields we need, plus a many_to_many with Author,
People and Subjects. Because:
- Books can have many authors, and many authors can have many books
Example: 27 Books by Multiple Authors That Prove the More, the Merrier
- Books can have many persons, and many persons can have many books
Example: Ron Weasley is in several Harry Potter books
- Books can have many subjects, and many subjects can have many books
Example: A book can be a comedy, fiction, and mystery at the same time
Let's create books/serializers.py:
"""
Serializers for the Books
"""
from django.db.utils import IntegrityError
from rest_framework import serializers
from books.models import Book, Author, People, Subject
from books.tasks import get_books_information
class AuthorInBookSerializer(serializers.ModelSerializer):
"""Serializer for the Author objects inside Book"""
class Meta:
model = Author
fields = ("id", "name")
class PeopleInBookSerializer(serializers.ModelSerializer):
"""Serializer for the People objects inside Book"""
class Meta:
model = People
fields = ("id", "name")
class SubjectInBookSerializer(serializers.ModelSerializer):
"""Serializer for the Subject objects inside Book"""
class Meta:
model = Subject
fields = ("id", "name")
class BookSerializer(serializers.ModelSerializer):
"""Serializer for the Book objects"""
author = AuthorInBookSerializer(many=True, read_only=True)
person = PeopleInBookSerializer(many=True, read_only=True)
subject = SubjectInBookSerializer(many=True, read_only=True)
class Meta:
model = Book
fields = "__all__"
class BulkBookSerializer(serializers.Serializer):
"""Serializer for bulk book creating"""
isbn = serializers.ListField()
def create(self, validated_data):
return_dict = {"isbn": []}
for isbn in validated_data["isbn"]:
try:
Book.objects.create(isbn=isbn)
return_dict["isbn"].append(isbn)
except IntegrityError as error:
pass
return return_dict
def update(self, instance, validated_data):
"""The update method needs to be overwritten on
serializers.Serializer. Since we don't need it, let's just
pass it"""
pass
class BaseAttributesSerializer(serializers.ModelSerializer):
"""A base serializer for the attributes objects"""
books = BookSerializer(many=True, read_only=True)
class AuthorSerializer(BaseAttributesSerializer):
"""Serializer for the Author objects"""
class Meta:
model = Author
fields = ("id", "name", "outside_url", "books")
class PeopleSerializer(BaseAttributesSerializer):
"""Serializer for the Author objects"""
class Meta:
model = People
fields = ("id", "name", "outside_url", "books")
class SubjectSerializer(BaseAttributesSerializer):
"""Serializer for the Author objects"""
class Meta:
model = Subject
fields = ("id", "name", "outside_url", "books")The most important serializer here is BulkBookSerializer. It's going to get an
ISBN list and then bulk create them in the DB.
On books/views.py, we can set the following views:
"""
Views for the Books
"""
from rest_framework import viewsets, mixins, generics
from rest_framework.permissions import AllowAny
from books.models import Book, Author, People, Subject
from books.serializers import (
BookSerializer,
BulkBookSerializer,
AuthorSerializer,
PeopleSerializer,
SubjectSerializer,
)
class BookViewSet(
viewsets.GenericViewSet,
mixins.ListModelMixin,
mixins.RetrieveModelMixin,
):
"""
A view to list Books and retrieve books by ID
"""
permission_classes = (AllowAny,)
queryset = Book.objects.all()
serializer_class = BookSerializer
class AuthorViewSet(
viewsets.GenericViewSet,
mixins.ListModelMixin,
mixins.RetrieveModelMixin,
):
"""
A view to list Authors and retrieve authors by ID
"""
permission_classes = (AllowAny,)
queryset = Author.objects.all()
serializer_class = AuthorSerializer
class PeopleViewSet(
viewsets.GenericViewSet,
mixins.ListModelMixin,
mixins.RetrieveModelMixin,
):
"""
A view to list People and retrieve people by ID
"""
permission_classes = (AllowAny,)
queryset = People.objects.all()
serializer_class = PeopleSerializer
class SubjectViewSet(
viewsets.GenericViewSet,
mixins.ListModelMixin,
mixins.RetrieveModelMixin,
):
"""
A view to list Subject and retrieve subject by ID
"""
permission_classes = (AllowAny,)
queryset = Subject.objects.all()
serializer_class = SubjectSerializer
class BulkCreateBook(generics.CreateAPIView):
"""A view to bulk create books"""
permission_classes = (AllowAny,)
queryset = Book.objects.all()
serializer_class = BulkBookSerializerEasy enough, endpoints for getting books, authors, people and subjects and an endpoint to post ISBN codes in a list.
We can check swagger to see all the endpoints created:

Now, how are we going to get all the data? 🤔
Creating a Celery task
Now that we have our project structure done, we need to create the asynchronous task Celery is going to run to populate our fields.
To get the information, we are going to use the OpenLibrary API.
First, we need to create books/tasks.py:
"""
Celery tasks
"""
import requests
from celery import shared_task
from books.models import Book, Author, People, Subject
def get_book_info(isbn):
"""Gets a book information by using its ISBN.
More info here https://openlibrary.org/dev/docs/api/books"""
return requests.get(
f"https://openlibrary.org/api/books?jscmd=data&format=json&bibkeys=ISBN:{isbn}"
).json()
def generate_many_to_many(model, iterable):
"""Generates the many to many relationships to books"""
return_items = []
for item in iterable:
relation = model.objects.get_or_create(
name=item["name"], outside_url=item["url"]
)
return_items.append(relation)
return return_items
@shared_task
def get_books_information(isbn):
"""Gets a book information"""
# First, we get the book information by its isbn
book_info = get_book_info(isbn)
if len(book_info) > 0:
# Then, we need to access the json itself. Since the first key is dynamic,
# we get it by accessing the json keys
key = list(book_info.keys())[0]
book_info = book_info[key]
# Since the book was created on the Serializer, we get the book to edit
book = Book.objects.get(isbn=isbn)
# Set the fields we want from the API into the Book
book.title = book_info["title"]
book.publish_date = book_info["publish_date"]
book.outside_id = book_info["key"]
book.outside_url = book_info["url"]
# For the optional fields, we try to get them first
try:
book.pages = book_info["number_of_pages"]
except:
book.pages = 0
try:
authors = book_info["authors"]
except:
authors = []
try:
people = book_info["subject_people"]
except:
people = []
try:
subjects = book_info["subjects"]
except:
subjects = []
# And generate the appropiate many_to_many relationships
authors_info = generate_many_to_many(Author, authors)
people_info = generate_many_to_many(People, people)
subjects_info = generate_many_to_many(Subject, subjects)
# Once the relationships are generated, we save them in the book instance
for author in authors_info:
book.author.add(author[0])
for person in people_info:
book.person.add(person[0])
for subject in subjects_info:
book.subject.add(subject[0])
# Finally, we save the Book
book.save()
else:
raise ValueError("Book not found")So when are we going to run this task? We need to run it in the serializer.
On books/serializers.py:
from books.tasks import get_books_information
...
class BulkBookSerializer(serializers.Serializer):
"""Serializer for bulk book creating"""
isbn = serializers.ListField()
def create(self, validated_data):
return_dict = {"isbn": []}
for isbn in validated_data["isbn"]:
try:
Book.objects.create(isbn=isbn)
# We need to add this line
get_books_information.delay(isbn)
#################################
return_dict["isbn"].append(isbn)
except IntegrityError as error:
pass
return return_dict
def update(self, instance, validated_data):
pass
To trigger the Celery tasks, we need to call our function with the delay
function, which has been added by the shared_task decorator. This tells Celery
to start running the task in the background since we don't need the result
right now.
Docker configuration
There are a lot of moving parts we need for this to work, so I created a
docker-compose configuration to help with the stack. I'm using the package
django-environ to handle all environment variables.
On docker-compose.yml:
version: "3.7"
x-common-variables: &common-variables
DJANGO_SETTINGS_MODULE: "app.settings"
CELERY_BROKER_URL: "redis://redis:6379"
DEFAULT_DATABASE: "psql://postgres:postgres@db:5432/app"
DEBUG: "True"
ALLOWED_HOSTS: "*,test"
SECRET_KEY: "this-is-a-secret-key-shhhhh"
services:
app:
build:
context: .
volumes:
- ./app:/app
environment:
<<: *common-variables
ports:
- 8000:8000
command: >
sh -c "python manage.py migrate &&
python manage.py runserver 0.0.0.0:8000"
depends_on:
- db
- redis
celery-worker:
build:
context: .
volumes:
- ./app:/app
environment:
<<: *common-variables
command: celery --app app worker -l info
depends_on:
- db
- redis
db:
image: postgres:12.4-alpine
environment:
- POSTGRES_DB=app
- POSRGRES_USER=postgres
- POSTGRES_PASSWORD=postgres
redis:
image: redis:6.0.8-alpineThis is going to set our app, DB, Redis, and most importantly our celery-worker instance. To run Celery, we need to execute:
$ celery --app app worker -l infoSo we are going to run that command on a separate docker instance
Testing it out
If we run
$ docker-compose upon our project root folder, the project should come up as usual. You should be able to open http://localhost:8000/admin and enter the admin panel.
To test the app, you can use a curl command from the terminal:
curl -X POST "http://localhost:8000/books/bulk-create" -H "accept: application/json" \
-H "Content-Type: application/json" -d "{ \"isbn\": [ \"9780345418913\", \
\"9780451524935\", \"9780451526342\", \"9781101990322\", \"9780143133438\" ]}"
This call lasted 147ms, according to my terminal.
This should return instantly, creating 15 new books and 15 new Celery tasks, one
for each book. You can also see tasks results in the Django admin using the
django-celery-results package, check its documentation.

Celery tasks list, using django-celery-results

Created and processed books list

Single book information

People in books

Authors

Themes
And also, you can interact with the endpoints to search by author, theme, people, and book. This should change depending on how you created your URLs.
That's it!
This surely was a LONG one, but it has been a very good one in my opinion. I've used Celery in the past for multiple things, from sending emails in the background to triggering scraping jobs and running scheduled tasks (like a unix cronjob)
You can check the complete project in my GitLab here: https://gitlab.com/rogs/books-app
If you have any doubts, let me know! I always answer emails and/or messages.
How I got a residency appointment thanks to Python, Selenium and Telegram python selenium telegram
Hello everyone
As some of you might know, I'm a Venezuelan 🇻🇪 living in Montevideo, Uruguay 🇺🇾. I've been living here for almost a year, but because of the pandemic my residency appointments have slowed down to a crawl, and in the middle of the quarantine they added a new appointment system. Before, there were no appointments, you just had to get there early and wait for the secretary to review your files and assign someone to attend you. But now, they had implemented an appointment system that you could do from the comfort of your own home/office. There was just one issue: there were never appointments available.
That was a little stressful. I was developing a small tick by checking the site multiple times a day, with no luck. But then, I decided I wanted to do a bot that checks the site for me, that way I could just forget about it and let the computers do it for me.
Tech
Selenium
I had some experience with Selenium in the past because I had to run automated tests on an Android application, but I had never used it for the web. I knew it supported Firefox and had an extensive API to interact with websites. In the end, I just had to inspect the HTML and search for the "No appointments available" error message. If the message wasn't there, I needed a way to be notified so I can set my appointment as fast as possible.
Telegram Bot API
Telegram was my goto because I have a lot of experience with it. It has a stupidly easy API that allows for superb bot management. I just needed the bot to send me a message whenever the "No appointments available" message wasn't found on the site.
The plan
Here comes the juicy part: How is everything going to work together?
I divided the work into four parts:
- Inspecting the site
- Finding the error message on the site
- Sending the message if nothing was found
- Deploy the job with a cronjob on my VPS
Inspecting the site
Here is the site I needed to inspect:
- On the first site, I need to click the bottom button. By inspecting the HTML,
I found out that its name is
form:botonElegirHora
- When the button is clicked, it loads a second page that has an error message
if no appointments are found. The ID of that message is
form:warnSinCupos.
Using Selenium to find the error message
First, I needed to define the browser session and its settings. I wanted to run it in headless mode so no X session is needed:
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
options = Options()
options.headless = True
d = webdriver.Firefox(options=options)
Then, I opened the site, looked for the button (form:botonElegirHora) and
clicked it
# This is the website I wanted to scrape
d.get('https://sae.mec.gub.uy/sae/agendarReserva/Paso1.xhtml?e=9&a=7&r=13')
elem = d.find_element_by_name('form:botonElegirHora')
elem.click()
And on the new page, I looked for the error message (form:warnSinCupos)
try:
warning_message = d.find_element_by_id('form:warnSinCupos')
except Exception:
passThis was working exactly how I wanted: It opened a new browser session, opened the site, clicked the button, and then looked for the message. For now, if the message wasn't found, it does nothing. Now, the script needs to send me a message if the warning message wasn't found on the page.
Using Telegram to send a message if the warning message wasn't found
The Telegram bot API has a very simple way to send messages. If you want to read more about their API, you can check it here.
There are a few steps you need to follow to get a Telegram bot:
- First, you need to "talk" to the Botfather to create the bot.
- Then, you need to find your Telegram Chat ID. There are a few bots that can help
you with that, I personally use
@get_id_bot. - Once you have the ID, you should read the
sendMessageAPI, since that's the only one we need now. You can check it here.
So, by using the Telegram documentation, I came up with the following code:
import requests
chat_id = # Insert your chat ID here
telegram_bot_id = # Insert your Telegram bot ID here
telegram_data = {
"chat_id": chat_id
"parse_mode": "HTML",
"text": ("<b>Hay citas!</b>\nHay citas en el registro civil, para "
f"entrar ve a {SAE_URL}")
}
requests.post('https://api.telegram.org/bot{telegram_bot_id}/sendmessage', data=telegram_data)The complete script
I added a few loggers and environment variables and voilá! Here is the complete code:
#!/usr/bin/env python3
import os
import requests
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from dotenv import load_dotenv
load_dotenv() # This loads the environmental variables from the .env file in the root folder
TELEGRAM_BOT_ID = os.environ.get('TELEGRAM_BOT_ID')
TELEGRAM_CHAT_ID = os.environ.get('TELEGRAM_CHAT_ID')
SAE_URL = 'https://sae.mec.gub.uy/sae/agendarReserva/Paso1.xhtml?e=9&a=7&r=13'
options = Options()
options.headless = True
d = webdriver.Firefox(options=options)
d.get(SAE_URL)
print(f'Headless Firefox Initialized {datetime.now()}')
elem = d.find_element_by_name('form:botonElegirHora')
elem.click()
try:
warning_message = d.find_element_by_id('form:warnSinCupos')
print('No dates yet')
print('------------------------------')
except Exception:
telegram_data = {
"chat_id": TELEGRAM_CHAT_ID,
"parse_mode": "HTML",
"text": ("<b>Hay citas!</b>\nHay citas en el registro civil, para "
f"entrar ve a {SAE_URL}")
}
requests.post('https://api.telegram.org/bot'
f'{TELEGRAM_BOT_ID}/sendmessage', data=telegram_data)
print('Dates found!')
d.close() # To close the browser connectionOnly one more thing to do, to deploy everything to my VPS
Deploy and testing on the VPS
This was very easy. I just needed to pull my git repo, install the
requirements.txt and set a new cron to run every 10 minutes and check the
site. The cron settings I used where:
*/10 * * * * /usr/bin/python3 /my/script/location/registro-civil-scraper/app.py >> /my/script/location/registro-civil-scraper/log.txtThe >> /my/script/location/registro-civil-scraper/log.txt part is to keep the logs on a new file.
Did it work?
Yes! And it worked perfectly. I got a message the following day at 21:00
(weirdly enough, that's 0:00GMT, so maybe they have their servers at GMT time
and it opens new appointments at 0:00).

Conclusion
I always loved to use programming to solve simple problems. With this script, I didn't need to check the site every couple of hours to get an appointment, and sincerely, I wasn't going to check past 19:00, so I would've never found it by my own.
My brother is having similar issues in Argentina, and when I showed him this, he said one of the funniest phrases I've heard about my profession:
> "Programmers could take over the world, but they are too lazy"
I lol'd way too hard at that.
I loved Selenium and how it worked. Recently I created a crawler using Selenium, Redis, peewee, and Postgres, so stay tuned if you want to know more about that.
In the meantime, if you want to check the complete script, you can see it on my Gitlab: https://gitlab.com/rogs/registro-civil-scraper
Introducing: YAMS (Yet Another Media Server)! docker dockercompose announcements opensource
Hello internet 😎
I'm here with a big announcement: I have created a bash script that installs my entire media server, fast and easy 🎉
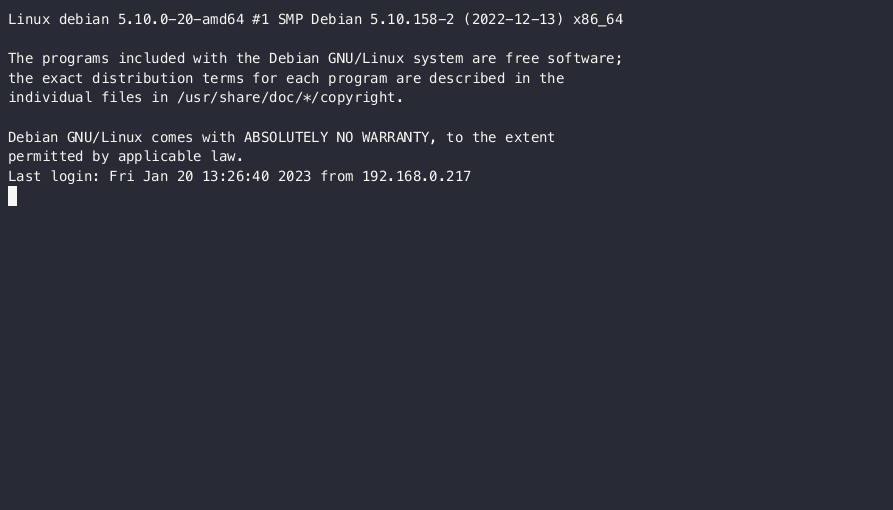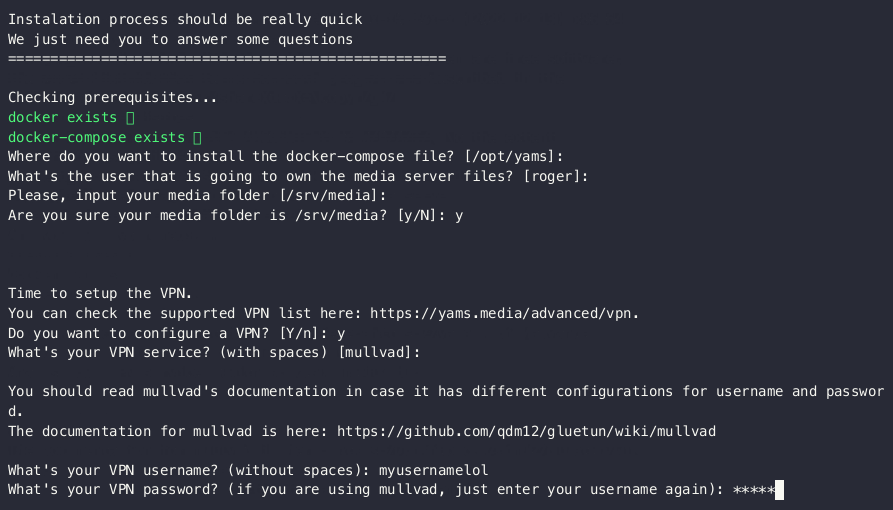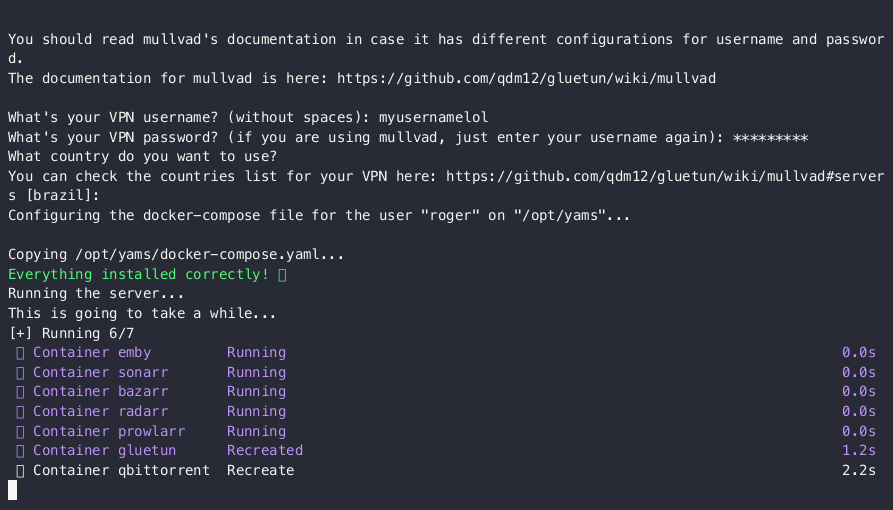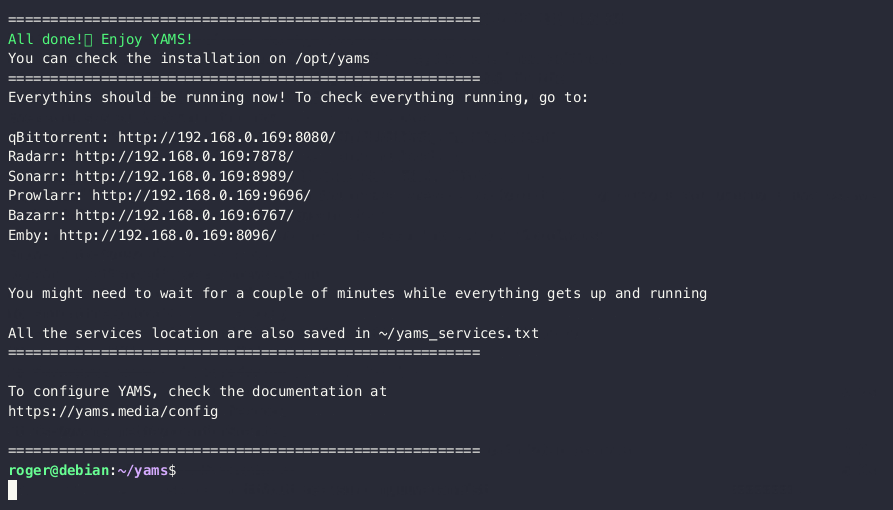
TL;DR
I've created YAMS. A full media server that allows you to download and categorize your shows/movies.
Go to YAMS's website here: http://yams.media or check it on Gitlab here: https://gitlab.com/rogs/yams.
A little history
When I first set up my media server, it took me ~2 weeks to install, configure and understand how it's supposed to work: Linking Sonarr, Radarr, Jackett together, choosing a good BitTorrent downloader, understanding all the moving pieces, choosing Emby, etc. My plan with YAMS is to make it easier for noobs (and lazy people like me) to set up their media servers super easily.
I have been working on YAMS for ~2 weeks. The docker-compose file has existed for almost 2 years but without any configuration instructions. Basically, you had to do everything manually, and if you didn't have any experience with docker, docker-compose, or any of the services included, it was very cumbersome to configure and understand how everything worked together.
So basically, I'm encapsulating my experience for anyone that wants to use it. If you don't like it, at least you might learn something from my experience, YAMS's docker-compose file or its configuration tutorial.
This is my first (and hopefully not last!) piece of open source software. I know it's just a bash script that sets up a docker-compose file, but seeing how my friends are using it and giving me feedback is exciting and addictive!
Why?
In 2019 I wanted a setup that my non-technical girlfriend could use without any problems, so I started designing my media server using multiple open source projects and running them on top of docker.
Today I would like to say it works very well 😎 And most importantly, I accomplished my goal: My girlfriend uses it regularly and I even was able to expand it to my mother, who lives 5000kms from me.
But then, my friends saw my setup…
On June 2022 I had a small "party" with my work friends at my apartment, and all of them were very impressed with my home server setup:
- "Sonarr" to index shows.
- "Radarr" to index movies.
- "qBittorrent" to download torrents.
- "Emby" to serve the server.
They kept telling me to create a tutorial, or just teach them how to set one up themselves.
I tried to explain the full setup to one of them, but explaining how everything connected and worked together was a big pain. That is what led me to create this script and configuration tutorial, so anyone regardless of their tech background and knowledge could start a basic media server.
So basically, my friends pushed me to build this script and documentation, so they (and now anyone!) could build it on their own home servers.
Ok, sounds cool. What did you do then?
A bash script that asks basic questions to the user and sets up the ultimate media server, with configuration instructions included! (That's the part I really REALLY enjoyed!)
What's included with YAMS?
Features
In no particular order:
- Automatic shows/movies download: Just add your shows and movies to the watch list and it should automatically download the files when they are available.
- Automatic classification and organization: Your media files should be completely organized by default.
- Automatic subtitles download: Self-explanatory. Your media server should automatically download subtitles in the languages you choose if they are available.
- Support for Web, Android, iOS, Android TV, and whatever that can support Emby: Since we are using Emby, you should be able to watch your favorite media almost anywhere.
Conclusion
You can go to YAMS's website here: https://yams.media.
I'm very proud of how YAMS is turning out! If you end up using it on your server, I just want to tell you THANK YOU 🙇 from the bottom of my heart. You are AWESOME!
Feedback is GREATLY appreciated (the VPN was added from the feedback!). I'm here to support YAMS for the long run, so I would like suggestions on how to improve the setup/website/configuration steps.
You can always submit issues on Gitlab if you find any problems, or you can contact me directly (email preferred!).
We also have a YAMS Matrix room! You can join here. See ya on the chat! 😀
Announcements announcements
All posts in here will have the category set to announcements.
Removing comments from my blog
I'm removing comments from my blog.
I've been thinking about this for a while, but I noticed that comments weren't being used and most posts were not that interesting. Don't get me wrong, I really appreciate your awesome comments, but running commento takes a lot of resources and I don't really see the full benefit of them.
From now on, if you want to leave a comment ("thank yous", suggestions, etc), you can send me an email. You'll find my email addess on the Contact page.
You have a good and relevant comment, I'll update the relevant post accordingly.